
Distributed tracing and distributed logging
How to debug in a distributed system?

Before talking about distributed tracing, we need to understand distributed logging and microservices architecture.
In a monolith application, logs are already centralized somewhere. We can search the logs easily without needing a complex log architecture to process application logs.
When comes to a microservices architecture, logs become more complicated. Imagine we have 100+ microservices and each service has its own logs. How can we search logs from distributed loggings? To solve this, we need a log aggregation layer to aggregate logs from different sources and centralize them.

Log Monitoring and Alerting

Last time, we talked about Observability. In this post, we are going to talk about log monitoring and alerting. It is also an important component of a system. Without this, your software engineers do not know what is happening in the whole system. That said, when an error occurs, no one knows and the engineering team does not know whether the system per…
Now, we centralized the logs but how can we know the sequence of logs and where the logs are from? For example:
Which service is my caller service?
Which service is my dependency service?
Which service is the first service that initiates the request?
Which service return errors?
How many services are involved in the call chain?
…
To solve these issues, we need Distributed Tracing to complement Distributed Logging.
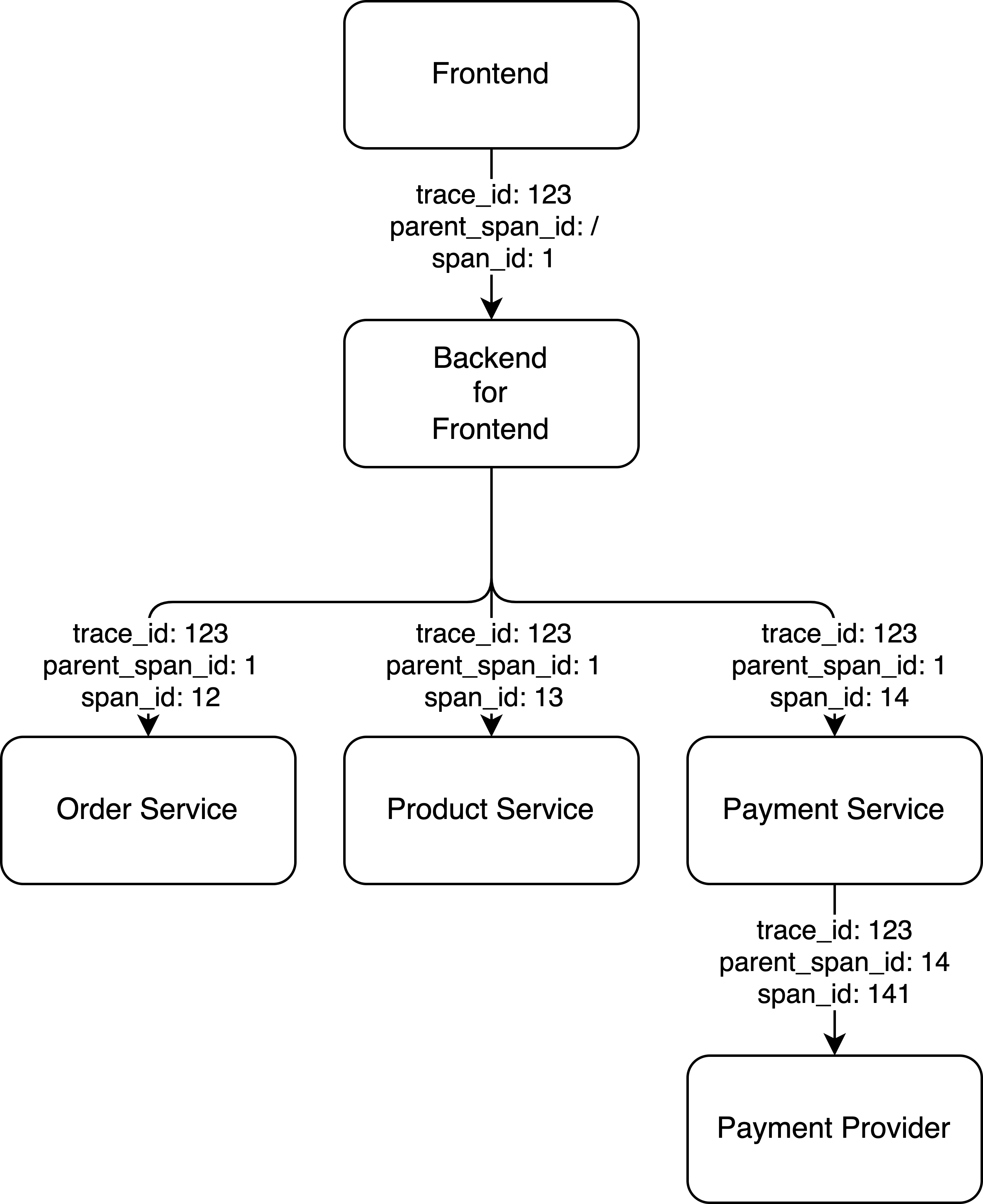
From the diagram, each request contains traceId, parentSpanId, and spanId. The service relationships are connected by using these IDs. For example, we can search traceId=123 to get all the logs and relationships for the request. We can also use other ids to narrow down the debugging scope.
Understand Observability

What is Observability? Observability is used to describe your system state so the software engineers can use that information to understand the system and identify issues. In a microservices architecture, log and trace are the important components. It helps software engineers to understand the current system behaviors and debugging. It can also be used to…
Overall, distributed tracing complements distributed logging by providing additional insights into the interactions and dependencies among microservices. It allows you to trace the flow of a request across different services, understand the sequence of events, and gain visibility into the performance and behavior of each service involved in the request.
How does it facilitate developers’ work?
Performance analysis: Developers can measure the time spent on each request and identify potential performance bottlenecks or areas for optimization within their microservices architecture.
Troubleshooting: When an error occurs, distributed tracing helps narrow down the scope of investigation by identifying the exact service responsible for the error. This allows developers to reach out to the respective service owner to address the issue efficiently.
Service dependencies: Visualizing the service dependencies through distributed tracing enables developers to understand how different microservices interact with each other, facilitating debugging and overall system comprehension.